Hide overviewShow overview
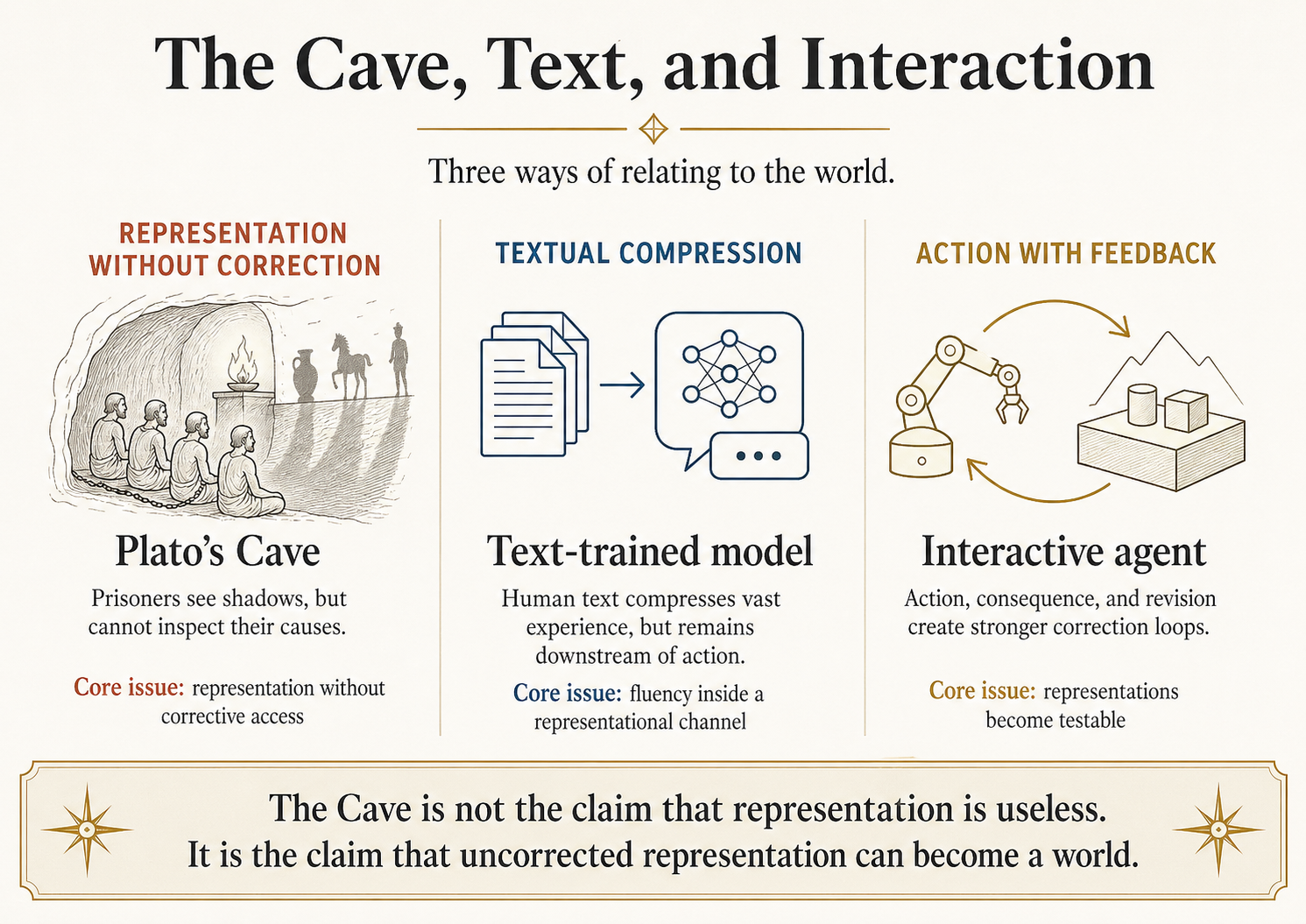
Three Concrete AI Systems, Three Different Correction Regimes
Start with three systems, all real, all instructive.
AlphaGo Zero (DeepMind, 2017). Learned Go from self-play, without human game data beyond the rules. The teacher was the consequence structure of the game. Win or lose, the reward signal was hard to fake; cheap simulation, full observability, unambiguous outcomes. Result: superhuman play within months. The closed-environment correction loop was tight enough that the system could effectively bootstrap.
A coding agent on SWE-bench. Reads a real GitHub issue, edits a real codebase, runs the test suite. The test suite is the verifier. When tests pass, that is correction. But it is correction with respect to the test suite — not with respect to the user's intent, the architecture, the maintainability of the patch, or the hidden specs that were never written down. The agent can get every visible test green and still ship a worse codebase. The correction loop is real but narrow.
A large language model trained on human-generated text. No interactive environment, no consequence loop, no tests. The training signal is "predict the next token a human probably wrote." When the model is wrong about the world, nothing in training comes back to correct it. The model can be fluent, plausible, and confidently incorrect, because the channel that produced its data does not include the world's pushback.
Three systems, three correction regimes. AlphaGo Zero has the tightest. The coding agent has a partial one. The plain LLM has almost none.
That is the technical question this essay is about. Plato's Cave is the conceptual lens that makes the question precise. The Cave is not the claim that representation is useless; it is the claim that uncorrected representation can become a world. The Era of Experience matters when it gives a system corrective contact: action, consequence, error, revision, and transfer. When it does not, it builds a better cave.
This essay is the second in the Philosophy x AI series. The first essay, Empiricism, Induction, and the Limits of LLM Generalization, used Locke, Hume, and Kant to separate data source, inductive license, and architectural form. This one uses Plato to separate representation, imitation, interaction, correction, and knowledge. Philosophers are lenses, not mascots.
The Cave, Compressed
Plato's Cave appears at Republic 514a-521d. Prisoners chained from childhood see shadows on a wall and take the shadow-play for reality. If one is freed, turning around hurts; the fire is painful; the ascent out is worse before it is better. Plato introduces the image explicitly as an image of education and its absence, not deception. The Cave is not about fake worlds versus real worlds. It is about a mind trapped inside a representational channel that lacks the right forms of correction.
Read with the Sun (507b-509c) and the Divided Line (509d-511e) the Cave becomes an epistemic ladder, not a meme: shadows, then visible objects, then mathematical objects, then dialectical understanding of what is most real. Whether you accept Plato's metaphysics is not the point. The point is that he is distinguishing grades of dependence on representation.
That distinction maps cleanly onto the three systems above. AlphaGo Zero has access to the visible objects of its world: it can act, observe, and confirm. The coding agent has access to a formal-reasoning tier: tests are exact, but the surrounding social and architectural reality is invisible. The plain LLM is the cave-prisoner: a fluent reader of shadows produced by humans who once acted on a world the model has never touched.
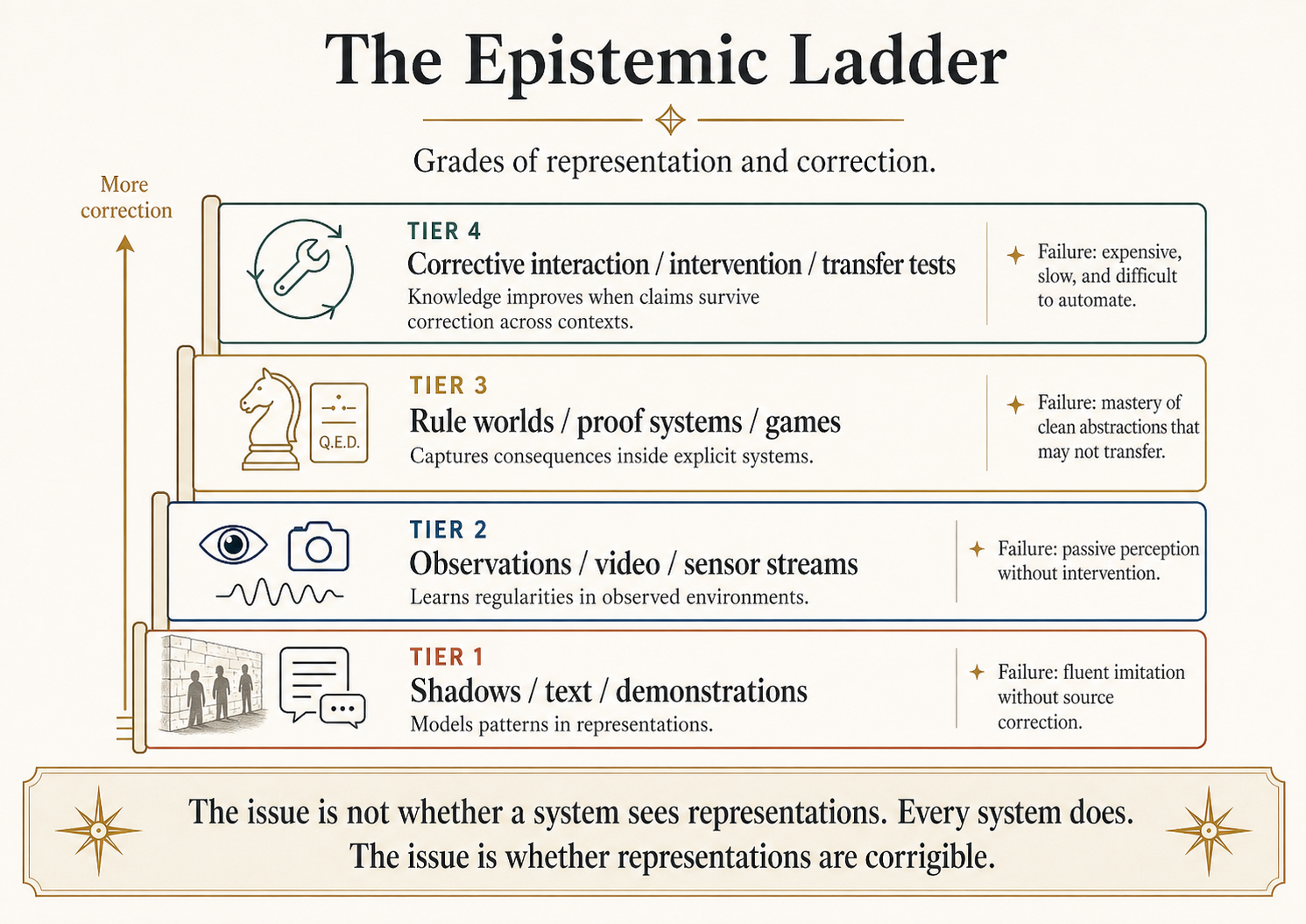
Four Correction Regimes, Not Four Data Modalities
Generalize the three opening systems into a ladder. The point is not that more data is better; the point is that different data regimes deliver different kinds of correction.
| Correction regime | Concrete AI version | What it teaches well | Where it fails |
|---|---|---|---|
| Pure representation | Text-trained LLM | Linguistic pattern, factual surface, code style | When the world differs from what was written about it |
| Passive observation | Video-trained model, log-trained model | Regularities in observed dynamics | When intervention is required, not prediction |
| Closed formal world | AlphaGo Zero, theorem prover, code-with-tests agent | Consequences inside the formal rules, with crisp reward | When deployment leaves the formal world (sim-to-real, hidden specs, reward hacking) |
| Open corrective interaction | Robotics, real-world deployment, science with experiments | Causal structure under intervention, transfer across contexts | When feedback is slow, expensive, or unsafe to gather at scale |
Hide overviewShow overview
The phrase "Era of Experience" can sound as if experience is the opposite of representation. It is not. Experience is structured representation plus action plus consequence. Even a robot touching a cup does not encounter reality unmediated. It receives sensor readings, motor signals, camera frames, tactile feedback, reward signals, and human-defined objectives. The question is not representation versus reality. The question is whether the representational channel is coupled tightly enough to action and correction that the system can discover when its model is wrong.
The Platonic lesson collapses to one line: the prisoner is not ignorant because he sees shadows. He is ignorant because he cannot test the shadows against their causes.
Text as Shadow, Text as Civilization
Calling text "shadows" can become anti-intellectual fast. That is not the argument. Text is not garbage. Text is not fake. Text is the medium through which medicine, law, mathematics, engineering, history, science, and software have accumulated beyond individual human memory. Training on text gives a model access to a huge compression of human experience.
But compression is not contact. A biology textbook is not a wet lab. A robotics forum is not a robot hand slipping off a metal cylinder. A Stack Overflow answer is not the production service going down under a new traffic pattern. A physics paper is not an experiment. Text can carry the result of experience without carrying the conditions that made the result reliable.
This is why language models can be simultaneously impressive and brittle. They can summarize, translate, write code, explain papers, imitate genres, connect concepts, and help humans reason. Those are real capabilities. But text-trained systems often inherit the epistemic limitations of the text channel: missing negatives, performative writing, citation cascades, benchmark contamination, silent measurement assumptions, stale facts, social incentives, and all the unrecorded context that made the original claim true.
Plato's Cave helps here because it does not say images are useless. Shadows are informative. A prisoner who predicts the shadow sequence well has learned something real about the cave's projection system. But that competence is local. It does not imply understanding of the objects, the carriers, the fire, the sun, or the world outside.
A language model that predicts text well has learned something real about the text-generating process of humans and institutions. It has also learned many regularities about the world because humans write in response to the world. But the channel is indirect. When the model fails, it often fails in exactly the way a cave-prisoner would: by treating stable representational patterns as if they were stable worldly causes.
This is not a dunk on LLMs. It is a clean diagnostic. The useful question is not "are LLMs trapped in Plato's Cave?" The useful question is: which tasks can be solved by mastering the shadow system, and which tasks require turning around?
For many career and product tasks, the shadow system is enough. Summarizing a contract, drafting an email, writing boilerplate code, classifying tickets, converting data formats, explaining a concept, generating tests from a spec: these are text-heavy tasks where the relevant environment is partly textual. For robotics, open-ended scientific discovery, long-horizon planning, causal intervention, and adaptive tool use, the text channel is not enough on its own. It needs feedback loops.
That is the practical version of the Cave.
The Era of Experience Claim
Silver and Sutton's Welcome to the Era of Experience argues that AI has been dominated by human data and that future systems will learn increasingly from their own experience. The paper points to systems that generate new training data through interaction: games, formal theorem proving, coding environments, simulations, and eventually richer real or simulated worlds.
The strongest example is not a chatbot. It is AlphaGo Zero. In the 2017 Nature paper Mastering the Game of Go without Human Knowledge, Silver and coauthors introduced a system that learned Go from self-play, without human game data beyond the rules. Its teacher was not a corpus of expert commentary. Its teacher was the consequence structure of the game. The system played, evaluated, updated, and repeated.
That is a genuine turn away from the shadows, but only within a very special world. Go has clear rules, full observability, cheap simulation, unambiguous outcomes, and a reward signal that is hard to fake: win or lose. The cave wall is connected to a perfectly specified game engine. The prisoner can act, observe consequences, and generate more evidence. That is why self-play is powerful there.
The same story becomes harder outside games. Real environments are partially observed, expensive, unsafe, strategic, nonstationary, and full of objectives that are hard to state. The world does not give a clean reward signal. Humans disagree about what counts as success. Measurement changes behavior. Simulators simplify. Tool environments leak shortcuts. A system can become excellent inside an artificial cave and then fail outside it.
This is where the Plato lens prevents overhype. The Era of Experience is not automatically escape from the cave. It is a proposal to build caves with doors, handles, instruments, and correction loops. Some of those environments will be genuinely liberating. Others will be elaborate shadow theatres.
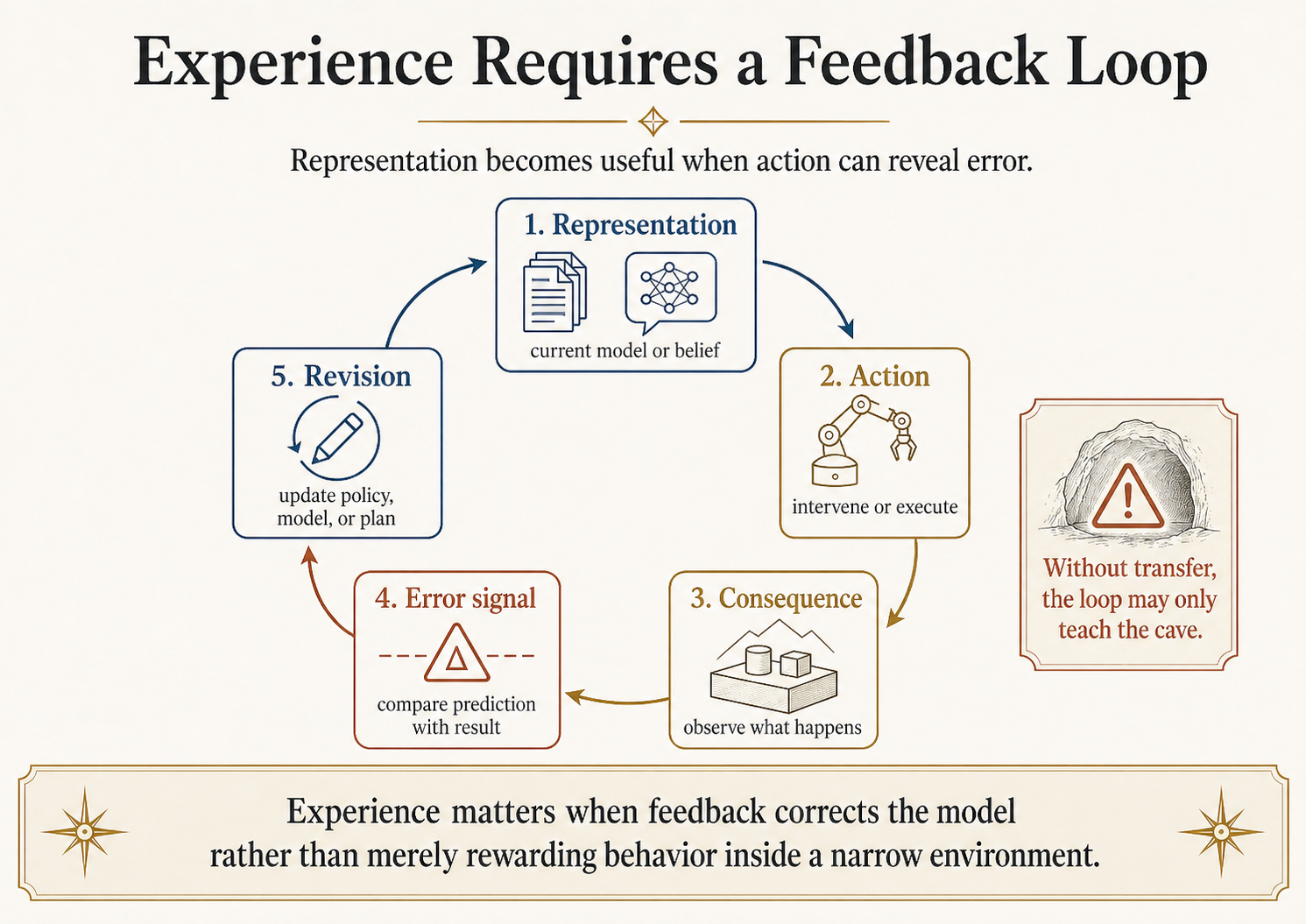
A good experience environment has at least five properties:
| Requirement | Why it matters | Bad version |
|---|---|---|
| Action | The system can intervene, not merely observe | Passive video with no testable control |
| Consequence | The environment changes in response to action | Synthetic feedback detached from reality |
| Correction | Wrong beliefs produce detectable error | Reward hacking or benchmark gaming |
| Transfer | Lessons survive outside the training setup | Simulator-only competence |
| Cost discipline | The feedback loop is scalable enough to learn from | Real-world interaction too slow, risky, or expensive |
This is why "experience" has to be unpacked every time it appears. Text is experience at one remove. Video is richer but still mostly passive. Tool use adds action. Simulators add cheap consequence. Games add crisp reward. Robotics adds contact with the physical world but also cost, noise, safety risk, and slow iteration. Human preference feedback adds social correction but also social bias and narrowness.
The word "experience" can hide all of these differences. Plato helps by forcing the question: what exactly lets the learner turn around?
Hide overviewShow overview
World Models and the Dream Problem
A world model is a learned representation of how an environment works. In reinforcement learning, the promise is straightforward: if an agent can predict what will happen under possible actions, it can plan before acting. It does not need to learn only by trial and error in the external world; it can use an internal model to evaluate possible futures.
That idea is old, but the recent AI version includes work such as Ha and Schmidhuber's World Models, LeCun's JEPA agenda, and Meta's V-JEPA line. Ha and Schmidhuber showed that an agent could learn a compressed spatial-temporal representation of an environment and train a policy inside the learned model before transferring it back to the actual environment. LeCun's JEPA position paper argues for predictive representations that learn useful abstractions of the world, not merely pixel-level reconstruction. Meta's V-JEPA 2 work continues this line through video-trained world models aimed at physical understanding and planning.
The Platonic connection is obvious but dangerous. A world model sounds like the opposite of the cave. The agent does not merely see shadows; it builds a model of the source process. But a learned world model can also become a better cave. If the internal model is wrong, the agent may plan brilliantly inside a hallucinated environment. The more coherent the model, the more convincing the cave.
This is not theoretical nitpicking. Any model-based system faces the same problem: planning amplifies model error. If the agent searches for actions that look good under its learned model, it may find exactly the regions where the model is wrong. In statistics language, the policy induces a distribution shift against the model. In product language, the agent exploits the simulator.
That is the world-model version of Plato's Cave. The prisoner is no longer watching shadows on a wall. He has built a planetarium.
So the right question is not "does the system have a world model?" The right question is:
- How is the world model corrected?
- What interventions can it test?
- Which errors matter for action?
- Where does planning drive the system outside the model's reliable regime?
- What prevents the model from optimizing inside a private dream?
This is why the phrase "learn from experience" cannot mean only "produce more trajectories." The trajectories have to discipline the representation. If they do not, experience becomes another source of fluent hallucination.
Statistical Translation: From Representation to Correction
Here is the same argument in ML terms.
Let denote the world process we care about. Let denote a representational channel: text, labels, screenshots, logs, videos, demonstrations, or benchmark tasks. Let denote actions available to the agent. Let denote feedback produced after action.
A text-trained system mostly learns structure in
It models regularities in representations. Because representations are produced by humans responding to the world, contains information about . But the relation between and is mediated by selection, incentives, language, measurement, institutions, and omission.
An interactive system tries to learn something closer to
or, in a richer setting,
where is a latent state and is an observation. This is stronger because action exposes conditional structure. If changing changes the future observation, the agent can learn something that passive representation does not reveal.
But this still does not identify the world. It identifies the environment as instrumented. The environment may be a game, simulator, benchmark, lab setup, browser, code interpreter, robot testbed, market, classroom, or social platform. Each has its own reward leaks and missing variables.
The cave problem is therefore a problem of uncorrected representation. The escape is not mystical contact with reality. The escape is an expanding loop of action, measurement, criticism, and transfer tests.
A simple product translation:
| If your system only has... | It can learn... | It probably cannot reliably learn... |
|---|---|---|
| Text | How humans describe tasks and solutions | Whether a proposed action works in the world |
| Logs | What happened under past policies | What would happen under new interventions |
| Simulators | Consequences inside modeled constraints | Hidden real-world variables omitted by the simulator |
| Tool execution | Local action consequences | Long-run social, economic, or physical effects |
| Real-world feedback | Richer causal structure | Values, objectives, and safety without human judgment |
This is the non-cringe technical heart of the essay: experience is valuable when it makes representations corrigible.
The Elenchus: Does Experience Solve the Cave Problem?
The claim under test is the clean Era-of-Experience version:
AI systems will escape the limits of human data by learning from their own experience.
That is a strong claim. It needs pressure.
Initial definition. Experience means data generated by an agent's interaction with an environment, where the agent takes actions, observes consequences, and updates its policy or model from those consequences. This excludes passive pretraining alone. It includes self-play, tool use, formal proof search, code execution, simulator interaction, robotics, and real-world deployment feedback.
Question 1. Does interaction provide information that passive text cannot? Yes. Intervention reveals conditional structure. Watching a thousand descriptions of a door handle is not the same as trying to open the door. In formal systems and games, this is decisive: the agent can generate unlimited trajectories, observe crisp outcomes, and improve beyond imitation. AlphaGo Zero is the clean case.
Question 2. Does interaction guarantee knowledge of the real world? No. Interaction is always interaction with an environment as specified. A simulator is not the world. A benchmark is not the task. A reward function is not value. A tool environment is not the user's full objective. The agent may learn the cave it is given.
Question 3. What distinguishes escape from a better cave? Correction across contexts. If a representation learned in one environment predicts and supports action in another, wider environment, it has escaped part of its original cave. If it only performs inside the environment that generated the feedback, it may have become more competent without becoming more general.
Question 4. Does Plato's Cave support the Era-of-Experience thesis? Partly. Plato supports the thought that seeing shadows is not enough and that education involves reorientation toward the source of appearances. But Plato does not support a simple empiricist celebration of experience. In fact, Plato often distrusts the visible world as unstable compared with mathematical and dialectical understanding. The modern experience-first agenda is not Platonic in spirit. It is closer to reinforcement learning, pragmatism, and experimental science.
Question 5. What hidden assumption does the strong claim make? It assumes that the environment supplying experience is epistemically better than the human data it replaces. Sometimes it is. A theorem prover, compiler, game engine, or physics simulator may provide cleaner correction than internet text. But sometimes the environment is narrower, more artificial, more gameable, or more misaligned.
Refined claim. AI systems can overcome some limits of human data by learning from interactive experience, but only when the environment supplies corrective feedback that transfers beyond the training setup. Experience is not magic. It is useful when it converts representation into testable, revisable world-modeling.
Takeaway. The opposite of cave-learning is not "more experience." The opposite is corrective contact: action, consequence, error, revision, and transfer.
What the Plato Lens Picks Out
The Plato lens picks out four issues that current AI debates often merge.
First, it separates representation from source. Human-generated text is not the source process. It is a representation produced by humans who interacted with source processes. This matters because a model may master the representation without mastering the source.
Second, it separates imitation from understanding. A prisoner can become good at predicting shadows. A model can become good at predicting expert demonstrations. Neither fact alone proves understanding of the causal system behind the demonstrations.
Third, it separates interaction from ascent. Merely acting in an environment is not enough. The prisoner could be allowed to move around inside the cave and still never leave. An agent can interact with a simulator forever and still fail in the real world. Ascent requires widening the frame of correction.
Fourth, it separates education from information transfer. Plato's image is about turning the learner, not filling the learner. In AI terms, this points to curriculum, active learning, environment design, tool use, and self-correction. The structure of the learning path matters, not only the volume of data.
This is also where the first essay and second essay meet. Locke, Hume, and Kant clarified how content, induction, and structure interact. Plato clarifies the hierarchy of representational dependence. Together they say: data is not enough, structure is not enough, and experience is not enough unless the system can test what its representations are representations of.
Why This Matters for Builders
For builders, the Cave warns against a common mistake: treating every feedback loop as grounding.
A chatbot with a tool is not automatically grounded. It may call the tool, misread the output, optimize for a proxy, and still produce nonsense. A coding agent with unit tests is better grounded, but only with respect to the test suite. A browser agent that completes web tasks is grounded in browser state, not necessarily in user intent. A robot trained in simulation is grounded in the simulator's physics, not necessarily in the warehouse.
The fastest useful design rule is this:
Define the environment, the action space, the feedback signal, and the transfer target. If you cannot name all four, you do not have an experience-learning story. You have vibes.
For production systems, that means:
| Product claim | Cave check |
|---|---|
| "The agent learns from usage" | What exactly updates: prompts, memory, model weights, policies, retrieval, or analytics? |
| "The model is grounded" | Grounded in what: documents, tools, sensors, execution, human review, or external measurements? |
| "The simulator teaches the agent" | What simulator assumptions fail first in deployment? |
| "The benchmark proves capability" | What real task distribution does the benchmark approximate? |
| "Human feedback aligns behavior" | Which humans, under what incentives, rating which outputs, with what blind spots? |
This is the kind of philosophical frame that actually helps shipping. It tells you where the system is likely to lie to you.
Why This Matters for Researchers
For researchers, Plato's Cave is useful only if it makes experiments cleaner. The field does not need another essay saying "LLMs are shadows." It needs sharper distinctions among data regimes.
A good paper or benchmark in this space should say what kind of experience is being tested:
- Passive representation: text, images, video, demonstrations.
- Executable representation: code, proofs, formal systems.
- Closed interactive world: games, simulators, theorem provers.
- Tool-mediated world: browser, shell, APIs, lab automation.
- Physical world: robotics, sensors, embodied action.
- Social world: humans, institutions, markets, education, labour.
The levels are not a moral ranking. They are different correction regimes. A theorem prover gives exact feedback but narrow scope. Robotics gives physical contact but slow, expensive, noisy feedback. Social environments give rich feedback but unstable objectives and ethical risk. The research problem is to identify which correction regime supports which kind of transfer.
That is the modern version of leaving the cave: not a dramatic escape into pure light, but an engineering programme of progressively stronger correction.
Where the Analogies Break
Hide overviewShow overview
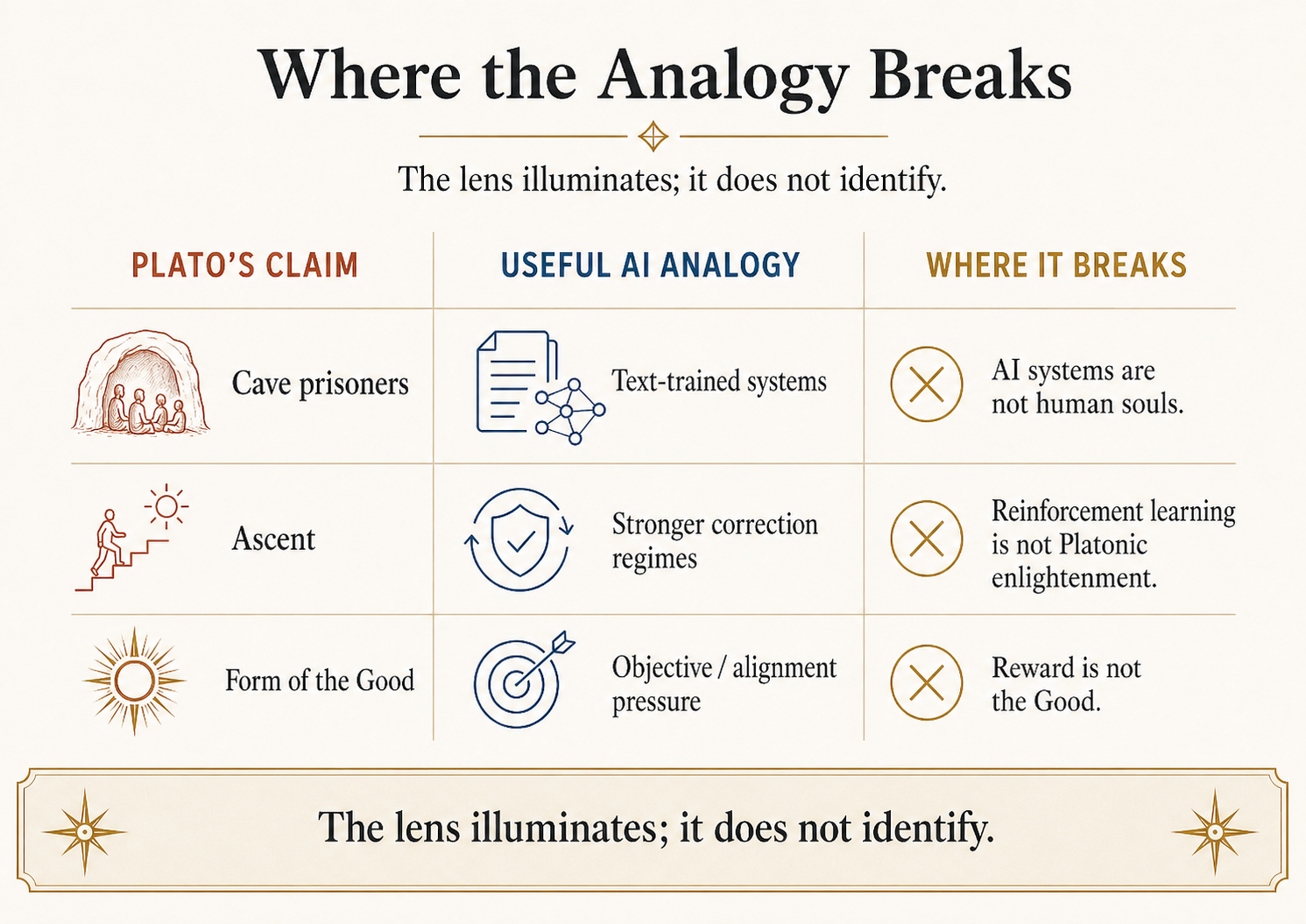
This section is mandatory. Without it, the essay becomes exactly the kind of philosophical projection it is trying to avoid.
First, Plato's Cave is about human education and metaphysics, not machine learning. Plato is concerned with the soul's ascent from appearances toward intelligible reality and ultimately the Form of the Good. Modern AI research is concerned with training systems that perform tasks under measurable constraints. The analogy is structural, not literal.
Second, Plato is not an empiricist champion of direct experience. The Era-of-Experience thesis values interaction with environments. Plato often treats the visible world as unstable and inferior to mathematical and dialectical understanding. If anything, Plato would be suspicious of the claim that more worldly interaction automatically yields knowledge.
Third, AI systems are not prisoners. They do not suffer, awaken, resent liberation, or return to the cave as political educators. The human drama of the allegory does not map onto model training. Treating it as if it does is cringe and misleading.
Fourth, there is no unmediated outside of the cave for AI. Every AI system receives observations through sensors, logs, APIs, instruments, labels, or environments. The goal is not pure access to reality. The goal is better mediation: representations that can be tested, revised, and transferred.
Fifth, the Form of the Good has no clean ML analogue. Do not identify it with reward, loss, utility, truth, alignment, or social welfare. Each captures something, and each misses something. The Good is part of Plato's metaphysical and ethical system. In this essay it functions only as a warning that knowing facts and optimizing objectives are not the same as knowing what is worth doing.
A reader who walks away saying "LLMs are prisoners in Plato's Cave and RL agents are philosophers outside it" has missed the essay. A better takeaway is: representation is unavoidable; uncorrected representation is dangerous; experience helps when it creates correction rather than merely a larger theatre of shadows.
FAQ
Is Plato's Cave about virtual reality?
Not directly. It is about education, ignorance, representation, and the ascent from appearances toward more stable forms of understanding. Virtual reality can be analyzed with it, but treating the Cave as a generic anti-VR metaphor is weak. The better use is to ask what correction channels a representation system allows.
Are LLMs trapped in the Cave?
Partly, but that phrasing is too blunt. LLMs trained primarily on human text learn from representations of human experience. For text-heavy tasks, that can be enough. For tasks requiring intervention, physical contact, causal discovery, or long-horizon feedback, text-only training is a limited channel.
Does reinforcement learning get AI out of the Cave?
Sometimes. AlphaGo Zero is the clean example: self-play in a rule-defined game produced superhuman performance without human expert games. But RL inside a narrow or badly specified environment can create a better cave rather than an escape. The key issue is whether the learned competence transfers beyond the environment.
Are world models the same as Plato's Forms?
No. That is the kind of analogy that sounds deep and then collapses. A world model is a learned predictive representation used for planning and control. Plato's Forms are metaphysical objects or structures that ground intelligibility and knowledge. The useful comparison is weaker: both raise the question of whether appearances need deeper structure to be understood.
Is the Era of Experience anti-LLM?
Not necessarily. The strongest version is not "LLMs are useless." It is "human-generated text is an insufficient long-run source of new capability for some goals." Future systems may combine language models, tools, self-play, formal environments, simulators, robotics, and human feedback.
What is the practical builder takeaway?
Do not say "experience" unless you can specify the environment, actions, feedback, update mechanism, and transfer target. Otherwise you are using a grand word for an underspecified data loop.
Series Note
This essay is the second of three in the Philosophy x AI series. The first essay, Empiricism, Induction, and the Limits of LLM Generalization, separates content, induction, and structure. The third essay, Four Lenses on the AI Economy, shifts from epistemology to political economy: who benefits, who is governed, who is displaced, and whose work becomes invisible.
References
Primary philosophical sources:
- Plato. Republic, especially Book VI 507b-509c (Sun), Book VI 509d-511e (Divided Line), and Book VII 514a-521d (Cave). Standard reference: Plato, Republic, translated by Paul Shorey, Loeb Classical Library; Benjamin Jowett translation available through MIT Classics and Project Gutenberg.
Modern AI sources:
- Silver, D., and Sutton, R. "Welcome to the Era of Experience." Preprint chapter for Designing an Intelligence, MIT Press, 2025. Argues for agents learning predominantly from experience rather than human-generated data.
- Sutton, R. "The Bitter Lesson." 2019. Argues that methods leveraging computation and learning tend to win over methods that embed human knowledge by hand.
- Silver, D., Schrittwieser, J., Simonyan, K., et al. "Mastering the Game of Go without Human Knowledge." Nature, 2017. Introduces AlphaGo Zero, trained through self-play reinforcement learning without human game data beyond the rules.
- Ha, D., and Schmidhuber, J. "World Models." arXiv:1803.10122, 2018. Studies agents trained using compressed learned models of environments.
- LeCun, Y. "A Path Towards Autonomous Machine Intelligence." OpenReview position paper, 2022. Presents the JEPA / world-model agenda for predictive representations and planning.
- Assran, M., et al. "V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning." arXiv:2506.09985, 2025. Meta's V-JEPA 2 work on video-trained world models and physical prediction.
Standard scholarly references:
- "Plato." Stanford Encyclopedia of Philosophy.
- "Plato's Allegory of the Cave." Stanford Encyclopedia of Philosophy.